Detecção de pneumonia em imagens de raio-X de tórax na plataforma Orange Machine Learning/Deep Learning
Orange é um ambiente de programação visual para projetos de ciência de dados e aprendizado de máquina. No Orange, os usuários podem arrastar e soltar componentes do tipo LEGO para construir uma solução completa, incluindo manipulação / visualização de dados e construção / treinamento / validação de modelos para seus projetos. Esta postagem ilustra o processo de desenvolvimento e comparação de diferentes modelos para classificação binária em imagens de raios-X de tórax normal e imagens de raios-X de tórax de pneumonia em Orange.
Aqui está um resumo sobre os dados, modelos e resultados:
- 1341 imagens de raios-X de tórax normais e 3875 imagens de raios-X de tórax de pneumonia;
- 66% para treinamento e 34% para validação;
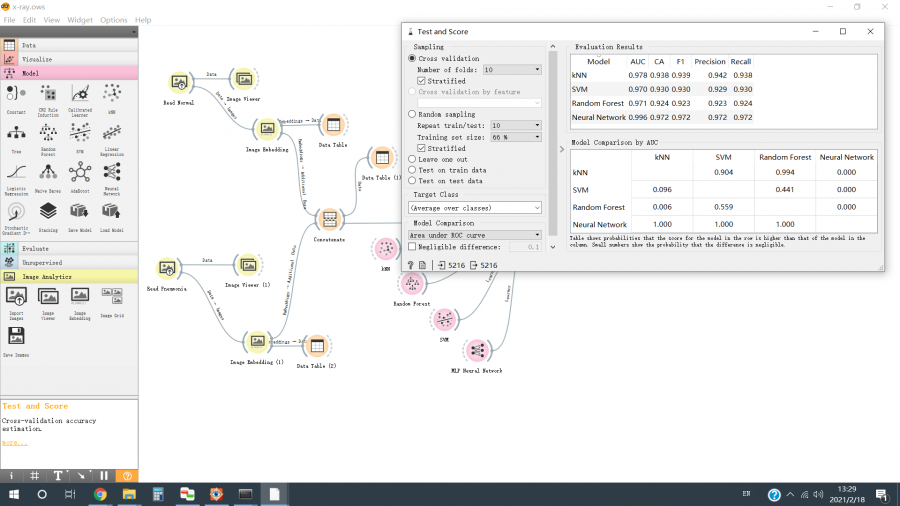
- O Inception v3 para extração de recursos e Multi-Layer Perceptron para classificação de recursos juntos atinge AUC como 0,996 e pontuação F1 como 0,972;
Este post é inspirado na classificação de imagens usando Orange – Prediction of Pneumonia from Chest X-Ray. A diferença entre o vídeo e esta postagem é que o foco do vídeo está no processo de previsão, enquanto a ênfase aqui é mostrar o processo de desenvolvimento e comparação de diferentes modelos.
O restante desta postagem está organizado da seguinte forma: introdução do conjunto de dados, desenvolvimento dos mecanismos para extração e classificação de recursos e apresentação dos resultados de desempenho de diferentes modelos.
Chest X-Ray Image Dataset
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
O conjunto de dados é organizado em 3 pastas (train / val / test) e contém subpastas para cada categoria de imagem (normal / pneumonia jpeg). A Tabela 1 mostra o número de imagens em todas as pastas. Este post usa apenas as pastas do trem para estudo.
Workflow – Pneumonia Image Classification
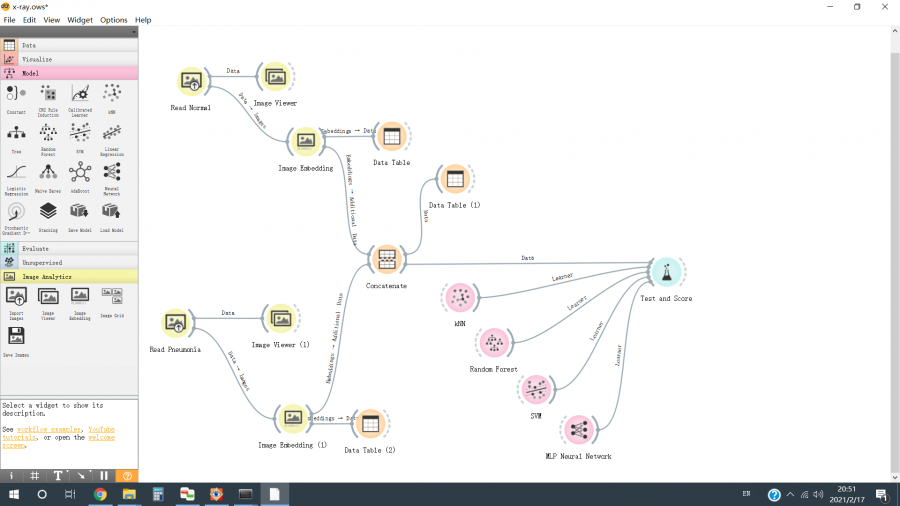
A Figura 2 mostra o fluxo de trabalho para construir, treinar e comparar nossos modelos.
- Ler imagens de raios-X de tórax normais e extrair seus recursos – [Figura 2 / parte superior esquerda] “Ler normal” usa o “Widget de importação de imagens” para ler as imagens de raios-X de tórax normais de “trem / normal”; “Image Embedding Widget” converte as imagens em seus recursos (o mecanismo será discutido mais tarde); “Image Viewer Widget” e “Data Table Widget” são usados para examinar as imagens e os recursos, respectivamente.
- Ler imagens de raios-X de tórax de pneumonia e extrair seus recursos – [Figura 2 / inferior esquerdo] “Ler Pneumonia” usa o “Widget de importação de imagens” para ler as imagens de raios-X de tórax de pneumonia de “trem / pneumonia”; “Image Embedding Widget” converte as imagens em seus recursos (o mecanismo será discutido mais tarde); “Image Viewer Widget” e “Data Table Widget” são usados para examinar as imagens e os recursos, respectivamente.
- Combine as listas de recursos de imagens de raios-X de tórax normais e imagens de raios-X de tórax de pneumonia – [Figura 2 / centro] O “widget Concatenar” combina as listas de recursos e atribui as fontes de imagens como rótulos.
- Treine e compare quatro classificadores de recursos – [Figura 2 / direita] Quatro classificadores de recursos, kNN, Random Forest, SVM e MLP Neural Network, são importados dos respectivos widgets. “Widget de teste e escopo” mostra os resultados finais.
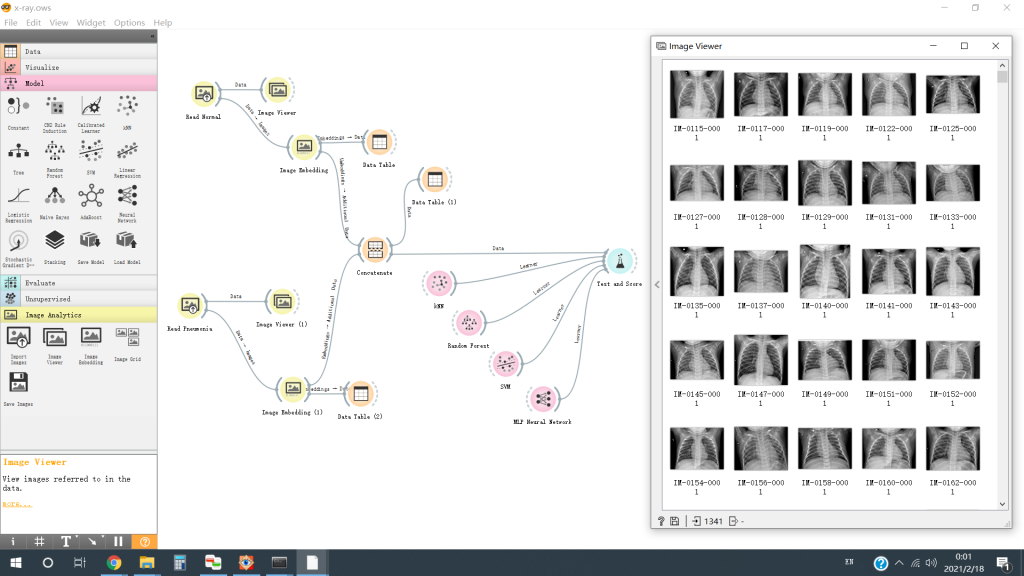
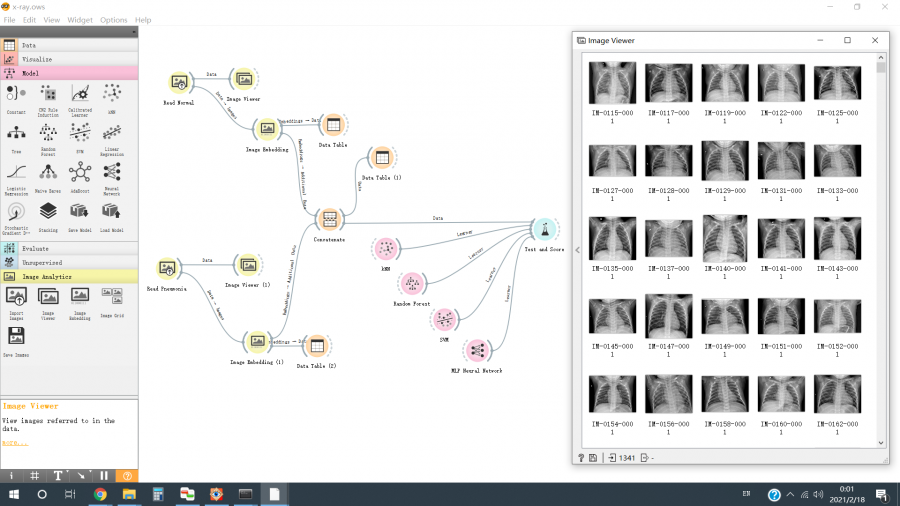
A Figura 3 mostra algumas imagens normais de raios-X de tórax exportadas pelo “Image Viewer Widget”.
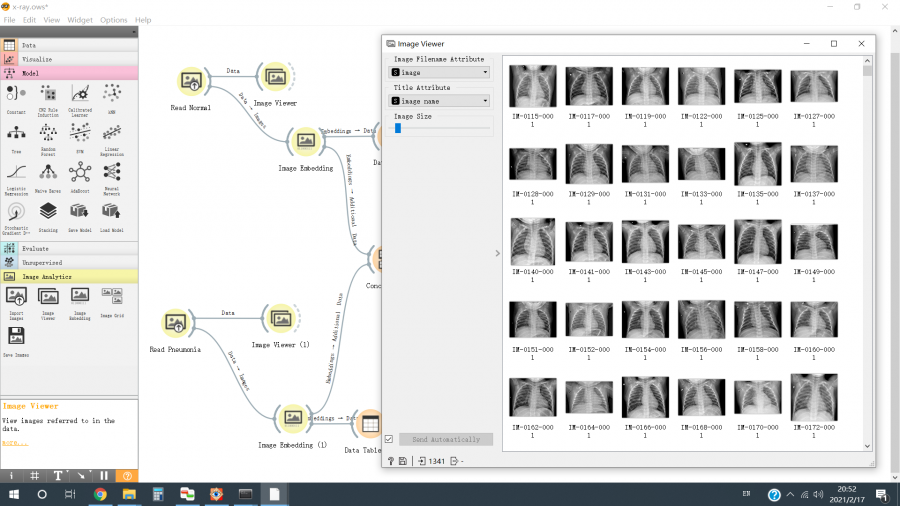
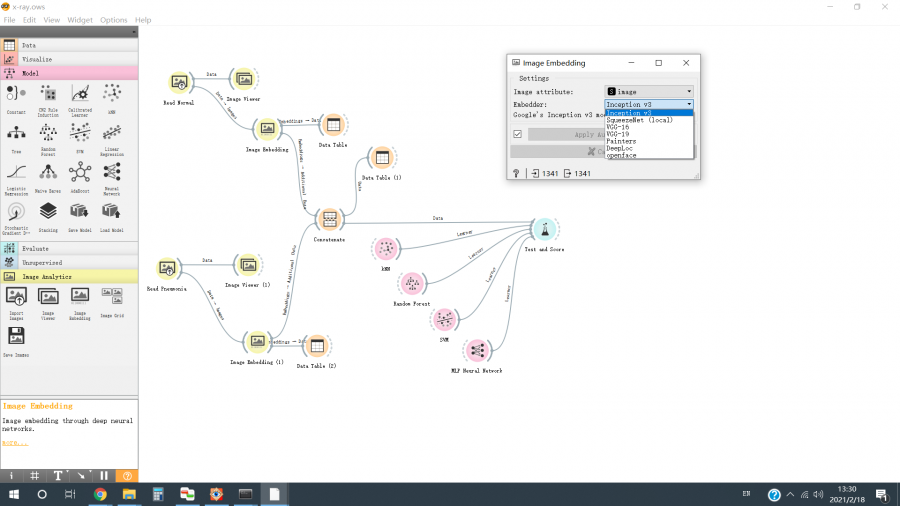
A Figura 4 mostra os modelos de aprendizado profundo (por exemplo, VGG16, VGG19, Inception V3, SqueezeNet, etc.) suportados pelo “Widget de incorporação de imagem”. O Inception v3 foi selecionado para estudo. Observação: o processo aqui é uma combinação de uma rede neural convolucional profunda pré-treinada para extração de recursos e um classificador tradicional ou um perceptron multicamadas para classificação de recursos. Por favor, verifique as referências para mais detalhes.
Avaliação de desempenho
A Figura 5 mostra as métricas de desempenho em quatro modelos de classificação, kNN, Random Forest, SVM e MLP Neural Network.
Conclusão
Como um programador acostumado a codificar linha por linha e desenvolver / comparar diferentes modelos para um problema específico em uma base de tentativa e erro, eu aprecio que a Orange forneceu uma solução tão elegante para classificação de imagens.
Em primeiro lugar, a Orange oferece uma maneira fácil de criar protótipos rápidos de ideias básicas, uma etapa essencial para obter insights de um novo problema. Em segundo lugar, o Orange serve de base para benchmarking e melhorias futuras, por exemplo, aplicação de modelos avançados, aprendizagem de transferência, aumento de dados, etc. Terceiro. provavelmente o mais importante, Orange demonstra a filosofia e os princípios para projetar um ambiente de programação visual para ciência de dados e aprendizado de máquina, como, usar modelos pré-treinados para obter incorporação, fornecer mecanismos simples para visualizar dados brutos e representações, etc.
Em contraste, a falta dos mais recentes modelos avançados de classificação de imagens de aprendizado profundo em Orange parece ser um pequeno revés na resolução de problemas.
Obrigado por ler o post. Se você tiver algum comentário, sinta-se à vontade para me deixar um recado.