6 truques de SQL que todo cientista de dados deve saber
Os cientistas/analistas de dados devem conhecer o SQL; de fato, todos os profissionais que trabalham com dados e análises devem conhecer o SQL. Até certo ponto, o SQL é uma habilidade subestimada para a ciência de dados, porque foi uma habilidade adquirida como necessária, porém não-legal, de extrair dados do banco de dados para alimentar o pandas e formas mais sofisticadas de organizar seus dados.
No entanto, com dados massivos sendo coletados e gerados todos os dias nos setores, desde que os dados residam em um banco de dados compatível com SQL, o SQL ainda é a ferramenta mais eficiente para ajudá-lo a investigar, filtrar e agregar para obter um entendimento completo de seus dados. Ao fatiar e filtrar com o SQL, os analistas podem identificar padrões que merecem uma análise mais aprofundada, o que muitas vezes leva a redefinir a população de análise e as variáveis a serem consideravelmente menores (que o escopo inicial).
Portanto, em vez de transferir grandes conjuntos de dados para Python ou R, a primeira etapa da análise deve ser o SQL para obter informações informativas de nossos dados.
Trabalhando em bancos de dados relacionais do mundo real, o SQL é muito mais do que apenas as instruções SELECT, JOIN, ORDER BY. Neste artigo, discutirei 6 dicas (e uma dica bônus) para tornar sua análise mais eficiente com o SQL e sua integração com outras linguagens de programação como Python e R.
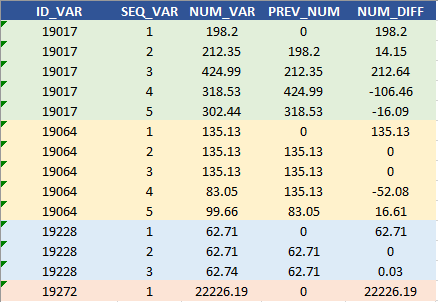
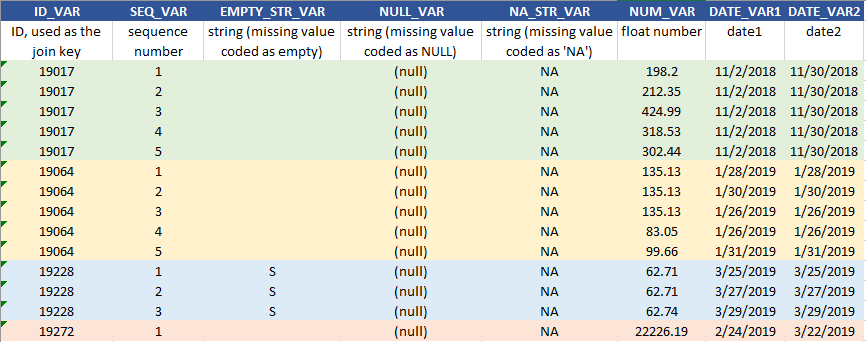
Para este exercício, trabalharemos com o Oracle SQL na tabela de dados de brinquedos(toys) abaixo, que consiste em vários tipos de elementos de dados.
1 – COALESCE() to recode NULL / missing data
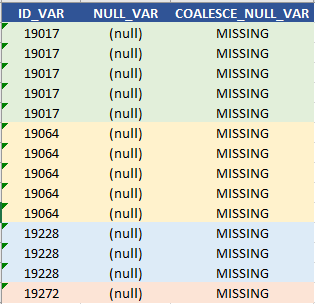
Quando se trata de recodificar valores ausentes, a função COALESCE () é o nosso molho secreto, que, sob essa circunstância, recodifica o NULL para qualquer valor especificado no segundo argumento. No nosso exemplo, podemos codificar novamente NULL_VAR para um valor de caractere ‘MISSING’,
---- 1) COALESCE() to recode the NULL value to the character string MISSING
SELECT
ID_VAR,
NULL_VAR,
COALESCE(NULL_VAR, 'MISSING') AS RECODE_NULL_VAR
FROM
CURRENT_TABLE
ORDER BY ID_VAR
esse snippet de código retorna,
Uma observação importante, no entanto, é que, nos bancos de dados, os valores ausentes podem ser codificados de várias maneiras, além de NULL. Por exemplo, eles podem ser uma string/espaço, ou branco/vazios (por exemplo, EMPTY_STR_VAR em nossa tabela) ou uma string de caracteres ‘NA’ (por exemplo, NA_STR_VAR em nossa tabela). Nesses casos, COALESCE () não funcionaria, mas eles podem ser manipulados com a instrução CASE WHEN,
--- However, COALESCE() NOT WORK for Empty or NA string, instead, use CASE WHEN SELECT ID_VAR, EMPTY_STR_VAR, COALESCE(EMPTY_STR_VAR, 'MISSING') AS COALESCE_EMPTY_STR_VAR, CASE WHEN EMPTY_STR_VAR = ' ' THEN 'EMPTY_MISSING' END AS CASEWHEN_EMPTY_STR_VAR, NA_STR_VAR, CASE WHEN NA_STR_VAR = 'NA' THEN 'NA_MISSING' END AS CASEWHEN_NA_STR_VAR FROM CURRENT_TABLE ORDER BY ID_VAR

2 – Calcular a frequência total e cumulativa em execução
A execução total pode ser útil quando estivermos interessados na soma total (mas não no valor individual) em um determinado ponto para uma possível segmentação da população da análise e identificação externa.
A seguir, mostramos como calcular a frequência total e cumulativa em execução para a variável NUM_VAR,
--- 2) Running total/frequency SELECT DAT.NUM_VAR, SUM(NUM_VAR) OVER (PARTITION BY JOIN_ID) AS TOTAL_SUM, ROUND(CUM_SUM / SUM(NUM_VAR) OVER (PARTITION BY JOIN_ID), 4) AS CUM_FREQ FROM ( SELECT T.*, SUM(NUM_VAR) OVER (ORDER BY NUM_VAR ROWS UNBOUNDED PRECEDING) AS CUM_SUM, CASE WHEN ID_VAR IS NOT NULL THEN '1' END AS JOIN_ID FROM CURRENT_TABLE T ) DAT ORDER BY CUM_FREQ
Nossa saída:
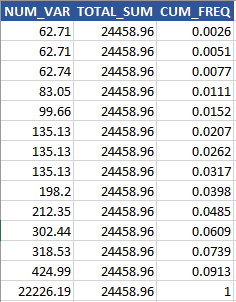
Dois truques aqui: (1) SUM sobre ROWS UNBOUNDED PRECEDING calcularão a soma de todos os valores anteriores até este ponto; (2) crie um JOIN_ID para calcular a soma total.
Usamos a função window para esse cálculo e, a partir da frequência cumulativa, não é difícil identificar o último registro como um outlier.
3 – Encontre o(s) registro(s) com valores extremos sem se associar
Portanto, nossa tarefa é retornar as linhas com o maior valor NUM_VAR para cada ID exclusivo. Uma consulta intuitiva é primeiro encontrar o valor máximo para cada ID usando o grupo por e, em seguida, associar-se automaticamente ao ID e ao valor máximo. No entanto, uma maneira mais concisa seria,
--- 3) Find the record having a number calculated by analytic functions (e.g., MAX) without self-joining
SELECT *
FROM
(
SELECT
DAT.*,
CASE WHEN (NUM_VAR = MAX(NUM_VAR) OVER (PARTITION BY ID_VAR)) THEN 'Y' ELSE 'N' END AS MAX_NUM_IND
FROM
CURRENT_TABLE DAT
) DAT2
WHERE MAX_NUM_IND = 'Y'
essa consulta deve fornecer a seguinte saída, mostrando as linhas com o máximo de NUM_VAR agrupados por ID,

4 – Cláusula condicional WHERE
Todo mundo conhece a cláusula WHERE no SQL para subconjunto. De fato, eu me vejo usando a cláusula condicional WHERE com mais frequência. Com a tabela de brinquedos, por exemplo, queremos apenas manter as linhas que satisfaçam a seguinte lógica,
— if SEQ_VAR in (1, 2, 3) & diff(DATE_VAR2, DATE_VAR1)≥ 0
— elif SEQ_VAR in (4, 5, 6) & diff(DATE_VAR2, DATE_VAR1) ≥1
— else diff(DATE_VAR2, DATE_VAR1) ≥2
Agora, a cláusula condicional WHERE é útil,
-- 4) Conditional where clause SELECT DAT.ID_VAR, DAT.SEQ_VAR, DAT.NUM_VAR, DATE_VAR1, DATE_VAR2, TRUNC(DATE_VAR2) - TRUNC(DATE_VAR1) AS LAG_IN_DATES FROM CURRENT_TABLE DAT WHERE (TRUNC(DATE_VAR2) - TRUNC(DATE_VAR1)) >= CASE WHEN SEQ_VAR IN (1,2,3) THEN 0 WHEN SEQ_VAR IN (4,5,6) THEN 1 ELSE 2 END ORDER BY ID_VAR, SEQ_VAR
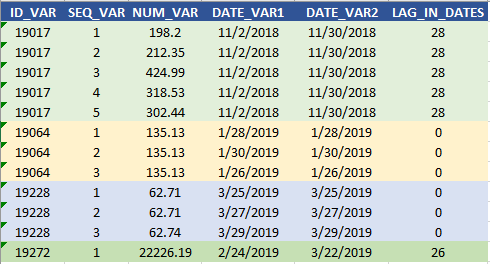
A lógica mencionada acima deve eliminar as seqüências 4, 5 do ID = 19064, porque a diferença entre date2 e date1 = 0, e é exatamente isso que a consulta retorna acima.
5 – Lag () e Lead () para trabalhar com linhas consecutivas
Lag (olhando para a linha anterior) e Lead (olhando para a próxima linha) provavelmente são duas das funções analíticas mais usadas no meu trabalho do dia a dia. Em poucas palavras, essas duas funções permitem que os usuários consultem mais de uma linha por vez sem se associarem.
Digamos que queremos calcular a diferença em NUM_VAR entre duas linhas consecutivas (classificadas por sequências),
--- 5) LAG() or LEAD() function SELECT DAT.ID_VAR, DAT.SEQ_VAR, DAT.NUM_VAR, NUM_VAR - PREV_NUM AS NUM_DIFF FROM ( SELECT T.*, LAG(NUM_VAR, 1, 0) OVER (PARTITION BY ID_VAR ORDER BY SEQ_VAR) AS PREV_NUM FROM CURRENT_TABLE T ) DAT ORDER BY ID_VAR, SEQ_VAR
A função LAG () retorna a linha anterior e, se não houver nenhuma (ou seja, a primeira linha de cada ID), o PREV_NUM é codificado como 0 para calcular a diferença mostrada como NUM_DIFF abaixo,
6 – Integrar consulta SQL com Python e R
O pré-requisito da integração de consultas SQL no Python e no R é estabelecer as conexões com o banco de dados via ODBC ou JDBC. Como isso está além do escopo deste blog, não discutirei aqui, no entanto, mais detalhes sobre como (criar conexões ODBC ou JDBC) podem ser encontrados aqui.
Agora, supondo que já conectamos Python e R ao nosso banco de dados, a maneira mais direta de usar a consulta, digamos Python, é copiá-la e colá-la como uma string e, em seguida, chamar pandas.read_sql (),
my_query = “SELECT * FROM CURRENT_TABLE”
sql_data = pandas.read_sql(my_query, connection)
Bem, desde que nossas consultas sejam curtas e finalizadas sem mais alterações, esse método funcionará bem. No entanto, e se a nossa consulta tiver 1000 linhas ou precisarmos atualizá-la constantemente? Para esses cenários, gostaríamos de ler arquivos .sql diretamente no Python ou R. O seguinte demonstra como implementar uma função getSQL no Python, e a idéia é a mesma no R,
import pandas as pd
def getSQL(sql_query,
place_holder_str,
replace_place_holder_with,
database_con):
'''
Args:
sql_query: sql query file
place_holder_str: string in the original sql query that is to be replaced
replace_place_holder_with: real values that should be put in
database_con: connection to the database
'''
sqlFile = open(sql_query, 'r')
sqlQuery = sqlFile.read()
sqlQuery = sqlQuery.replace(place_holder_str, replace_place_holder_with)
df = pd.read_sql_query(sqlQuery, database_con)
database_con.close()
return df
Aqui, o primeiro arg sql_query obtém um arquivo .sql independente e separado que pode ser facilmente mantido, como este,
SELECT
*
FROM
CURRENT_TABLE DAT
WHERE
ID_VAR IN ('ID_LIST')
ORDER BY ID_VAR, SEQ_VAR
O “ID_LIST” é uma string de espaço reservado para os valores que estamos prestes a inserir e o getSQL () pode ser chamado usando o seguinte código,
seq12_df = getSQL('SQL_FILE.sql', 'ID_LIST', "','".join(['19228', '19272']), database_con=conn)
Bônus, expressão regular em SQL
Embora eu não use expressões regulares no SQL o tempo todo, às vezes pode ser conveniente para a extração de texto. Por exemplo, o código a seguir mostra um exemplo simples de como usar REGEXP_INSTR () para localizar e extrair números (consulte aqui para obter mais detalhes),
-- Find and extract numbers between 0 - 9 that consecutively happens 5 times
SELECT
SUBSTRING(LONG_TEXT, REG_IDX, REG_IDX+5) AS NUMBER_LIST_FOUND
FROM
(
SELECT
REGEXP_INSTR(LONG_TEXT, '[0-9]{5}') AS REG_IDX,
LONG_TEXT
FROM
BONUS
) DAT
Espero que você ache esta dica útil, se tiver alguma dúvida ou comentário, fala pra gente!
Fonte:https://towardsdatascience.com/6-sql-tricks-every-data-scientist-should-know-f84be499aea5