Visão 360º do Consumidor – Sistema Relacional

Parte II – Implementando um aplicativo C360 em um sistema relacional
O objetivo desta seção é apresentar brevemente como construir um sistema relacional para armazenar os dados do C360. Esta seção não serve como uma introdução completa à esta classe de arquitetura de sistema. Em vez disso, nosso objetivo é apresentar o mínimo necessário para compreender as complexidades de usar um sistema relacional para um aplicativo C360.
| client_id | name | acct_id | loan_id | cc_num |
| client_0 | Fabiano | acct_14 | loan_32 | cc_17 |
| client_1 | Patricia | acct_14 | none | none |
| client_2 | Trevisan | acct_5 | none | cc_32 |
| client_3 | Franco | acct_0 | loan_18 | none |
| client_4 | Thammy | acct_0 | [loan_18, loan_80] | none |
As tecnologias que usaremos para ilustrar uma implementação relacional são SQL e Postgres. SQL, que significa Structured Query Language, é a linguagem de programação usada para se comunicar com um banco de dados relacional. Optamos por usar o RDBMS Postgres devido à sua ampla aplicabilidade e origens na comunidade de código aberto.
Modelo de Dados
Depois de chegar a um acordo sobre um modelo conceitual, como aquele mostrado no primeiro artigo, você pode prosseguir para o projeto de seu banco de dados relacional. Tradicionalmente, você criaria um diagrama entidade-relacionamento, ou ERD. Um ERD é uma representação lógica de seu modelo de dados e é um ponto de partida típico para um design de banco de dados relacional.
Na imagem abaixo, cada quadrado representa uma entidade que se tornará uma tabela no banco de dados relacional. Os atributos, ou propriedades descritivas sobre cada entidade, são listados dentro de cada quadrado. Conforme já visto nos dados, cada entidade terá um identificador único. Cada cliente será identificado exclusivamente por seu client_id, uma conta por seu acct_id e assim por diante. Os clientes também têm nomes e, em aplicativos maiores, outros atributos.
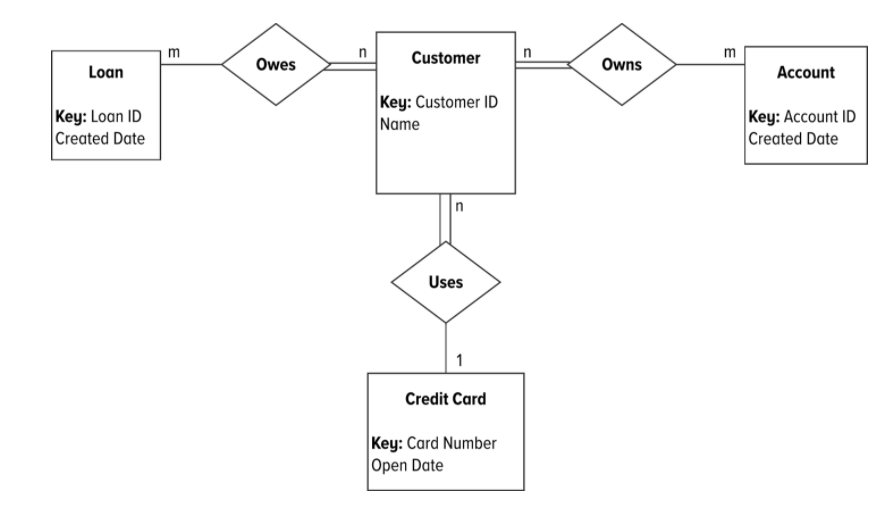
As formas de losango entre as entidades representam a conexão de uma entidade a outra. A cardinalidade da conexão é indicada acima e abaixo ou à esquerda e à direita da forma de diamante. Nestes dados, temos dois tipos de conexões: um para muitos e muitos para muitos.
Muitos para muitos
Vamos começar com a conexão um para muitos que é mostrada entre clientes e cartões de crédito. Neste exemplo, um cliente pode ter vários cartões de crédito, mas um cartão de crédito só pode pertencer a um cliente. Essa conexão um para muitos descreve a cardinalidade entre clientes e cartões de crédito e é ilustrada com a conexão n para 1 entre clientes e cartões de crédito.
O outro tipo de conexão que vemos em nossos dados é uma conexão muitos para muitos. Existem duas conexões muitos para muitos em nossos dados: clientes para contas e clientes para empréstimos. Sabemos por nossos dados que um cliente pode ter muitas contas e uma conta pode ter muitos clientes. O mesmo se aplica aos empréstimos.
Dizemos que os clientes para empréstimos são uma conexão muitos para muitos e ilustramos isso na imagem com notação n para m na conexão. Antes de criar tabelas e inserir dados, precisamos traduzir nosso modelo de dados lógico em um modelo físico modelo de dados.
Diagrama ERD
Especificamente, precisamos traduzir as entidades e conexões do ERD em tabelas com chaves primárias e estrangeiras. Uma chave primária é uma parte de identificação exclusiva dos dados, como o ID do cliente ou o número do cartão de crédito, que usaremos para acessar as informações em sua tabela.
Uma chave estrangeira é uma parte de identificação exclusiva dos dados que usaremos para acessar as informações em uma tabela diferente, como armazenar a ID de um cliente junto com as informações do cartão de crédito.
Armazenamos um ID de cliente com as informações do cartão de crédito do cliente para que possamos usá-lo para consultar todas as suas informações em uma tabela diferente, ou seja, na tabela do cliente.
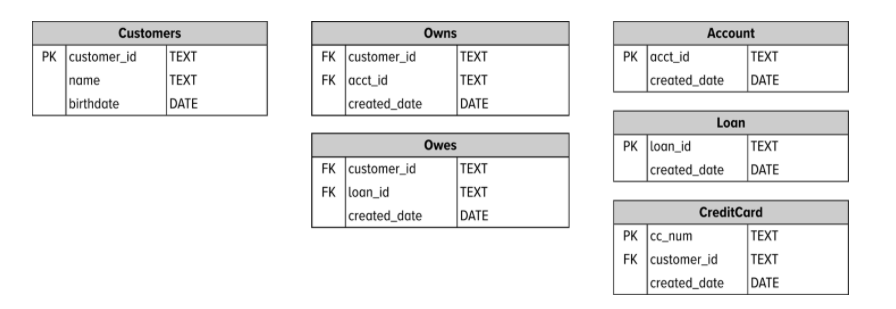
Esperávamos ver pelo menos quatro tabelas uma tabela para cada entidade.
Especificamente, tem uma tabela por tipo de entidade: cliente, conta, empréstimo e cartão de crédito. Para cada uma dessas tabelas, vemos atributos adicionais que descrevem a entidade. O atributo mais importante para cada uma dessas entidades é sua chave primária.
Cada chave primária é indicada com um PK próximo à linha. As chaves primárias que temos para cada tabela são customer_id, acct_id, loan_id e cc_num, respectivamente. Esses são os identificadores exclusivos que usaremos para pesquisar uma linha específica de informações na tabela.
Antes de falarmos sobre as outras duas tabelas, vamos examinar a tabela CreditCard. Esta tabela possui uma chave primária e uma chave estrangeira. Estamos usando uma chave estrangeira nesta tabela para rastrear o relacionamento um-para-muitos que criamos em nosso ERD. O customer_id é a chave estrangeira (indicada com um FK) que nos dará a capacidade de relacionar as informações do cartão de crédito a um cliente exclusivo.
Um para muitos
Construir um relacionamento um para muitos em seu modelo de dados físico pode ser tão fácil quanto adicionar uma chave estrangeira para uni-lo de volta a outra tabela de entidades.
As duas últimas tabelas para entender em nosso modelo de dados físico são as tabelas Owns e Owes. Essas tabelas são tabelas de junção que nos permitem armazenar fisicamente as conexões muitos para muitos em nossos dados.
A tabela Owns armazena as várias conexões observadas entre os clientes e as contas que eles possuem. A tabela Owes armazena as muitas conexões observadas entre os clientes e os empréstimos que eles devem. Como cada cliente pode possuir uma conta apenas uma vez e deve um empréstimo apenas uma vez, a chave primária dessas tabelas de junção é uma combinação das duas chaves estrangeiras.
Por exemplo, a tabela Owns armazena pelo menos duas informações sobre cada linha da tabela: o identificador único do cliente e o identificador único da conta. Dada uma linha desta tabela, podemos acessar o identificador exclusivo do cliente para juntar de volta à tabela do cliente e o identificador exclusivo da conta para juntar de volta à tabela da conta. Essa tabela de junção é uma maneira comum de representar uma conexão muitos para muitos em um sistema relacional.