Conheça o Amundsen – Catálogo de dados da Lyft
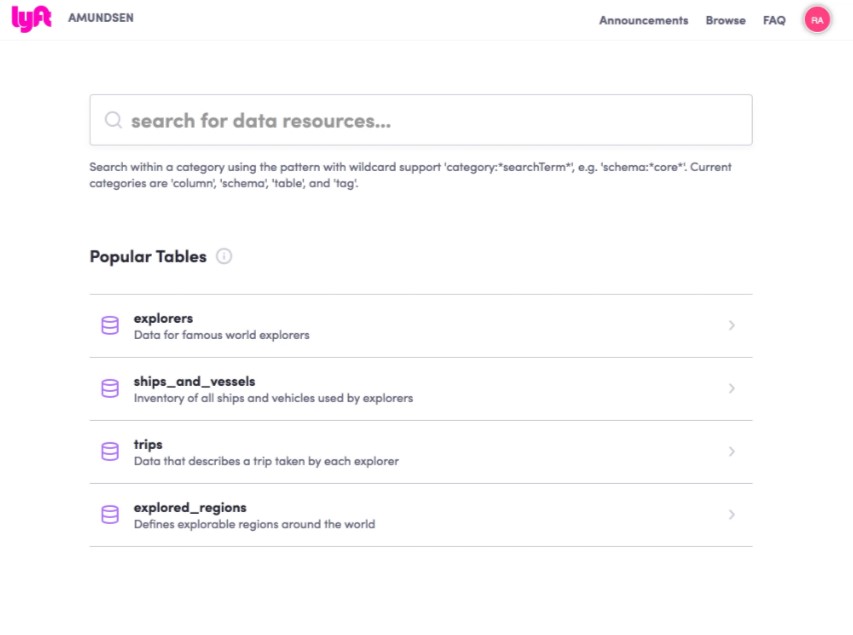
Para aumentar a produtividade dos cientistas de dados e pesquisadores da Lyft, desenvolvemos um aplicativo de descoberta de dados baseado em um mecanismo de metadados. Com o codinome Amundsen (em homenagem ao explorador norueguês Roald Amundsen), melhoramos a produtividade de nossos usuários de dados fornecendo uma interface de pesquisa de dados semelhante a esta:
O problema
Os dados no nosso mundo cresceram 40 vezes nos últimos 10 anos — veja o gráfico abaixo da Comissão Económica das Nações Unidas para a Europa (UNECE).

O crescimento sem precedentes nos volumes de dados levou a dois grandes desafios:
- Produtividade — Seja construindo um novo modelo, instrumentando uma nova métrica ou fazendo análises ad hoc, como posso usar esses dados de maneira mais produtiva e eficaz?
- Conformidade — Ao coletar dados sobre os usuários de uma empresa, como as organizações cumprem as crescentes demandas regulatórias e de conformidade e mantêm a confiança de seus usuários?
A chave para resolver estes problemas não está nos dados, mas nos metadados. E, para mostrar como, vamos percorrer uma jornada de como resolvemos parte do problema de produtividade na Lyft usando metadados.
Os metadados são o Santo Graal das aplicações futuras
Em sua essência, os metadados são um conjunto de dados que descreve e fornece informações sobre outros dados.
Os metadados possuem duas partes: um conjunto de dados (geralmente menor) que descreve outro conjunto de dados (geralmente maior).
1-Um conjunto descritivo de dados – ABC de metadados
Três grandes tipos de metadados se enquadram nesta categoria:
Contexto do aplicativo – informações necessárias para a operação de humanos ou aplicativos. Isso inclui a existência de dados e descrição, semântica e tags associadas aos dados.
Comportamento — informações sobre como os dados são criados e usados ao longo do tempo. Isto inclui informações sobre propriedade, criação, padrões de uso comuns, pessoas ou processos que são usuários frequentes, proveniência e linhagem.
Mudança — informações sobre como os dados mudam ao longo do tempo. Isso captura informações sobre a evolução dos dados (por exemplo, a evolução do esquema de uma tabela) e os processos que os criam (por exemplo, o código ETL relacionado para uma tabela).
Capturar esses três tipos de metadados e usá-los para impulsionar aplicativos é fundamental para muitas aplicações do futuro. ABC de metadados é uma terminologia adotada de um artigo no Ground de Joe Hellerstein, Vikram Sreekanti et al.
2 – Os dados que estão sendo descritos
Agora vamos falar sobre quais dados estão sendo descritos pelo ABC acima. A resposta curta é quaisquer dados da sua organização. Isso inclui, mas não está limitado a:
- Armazenamentos de dados — tabelas, esquemas, documentos de armazenamentos de dados estruturados como Hive, Presto, MySQL, bem como armazenamentos de dados não estruturados (como S3, Google Cloud Storage, etc.)
- Painéis/relatórios – consultas, relatórios e painéis salvos em ferramentas de BI/relatórios como Tableau, Looker, Apache Superset, etc.
- Eventos/Esquemas — Eventos e esquemas armazenados em registros de esquema ou ferramentas como Segment.
- Streams — Streams/tópicos em Apache Kafka, AWS Kinesis, etc.
- Processamento – trabalhos ETL, fluxos de trabalho de ML, trabalhos de streaming, etc.
- Pessoas – não me refiro a uma pilha de software, quero dizer boas e velhas pessoas como você e eu, que carregamos dados em nossas cabeças e em nossa estrutura organizacional, portanto, informações como nome, equipe, cargo, recursos de dados usados com frequência, recursos de dados marcados são todas as informações importantes nesta categoria.
Esses metadados exatos podem ser usados para tornar os usuários de dados mais produtivos, fornecendo-lhes os metadados relevantes na ponta dos dedos.
Produtividade
No nível de 50.000 pés, o fluxo de trabalho do cientista de dados é semelhante ao seguinte.
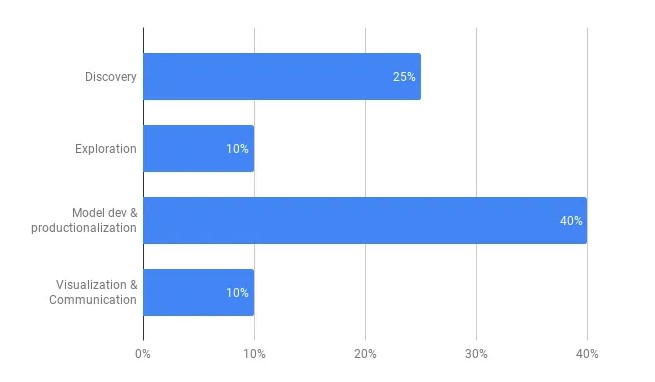
Na Lyft, o que observamos foi que, embora quiséssemos que a maior parte do tempo fosse gasta no desenvolvimento de modelos (também conhecido como prototipagem) e na produção, grande parte do tempo era gasto na descoberta de dados.
A descoberta de dados inclui encontrar a resposta para perguntas como:
- Esses dados existem? Cadê? Qual é a fonte da verdade desses dados? Eu tenho acesso a ele?
- Quem e/ou qual equipe é a proprietária? Quem são os usuários comuns?
- Existe trabalho existente que eu possa reutilizar?
- Posso confiar nesses dados?
Se eles parecem familiares, nós entendemos você.
A ideia de Amundsen foi muito inspirada em motores de busca como o Google – na verdade, muitas vezes pensamos nisso como “Pesquisa de dados” dentro da organização.
O que apresentamos a seguir são simulações com dados falsos, para lhe dar uma ideia de como é usar Amundsen.
Página inicial:
O ponto de entrada para a experiência é uma caixa de pesquisa onde você pode digitar em inglês simples para pesquisar dados, por exemplo. “resultados eleitorais” ou “usuários”. Se você não sabe o que está procurando, apresentamos uma lista de tabelas populares na organização para navegar por elas.
Classificação de pesquisa:
Depois de inserir o termo de pesquisa, serão exibidos os resultados da pesquisa da seguinte forma.
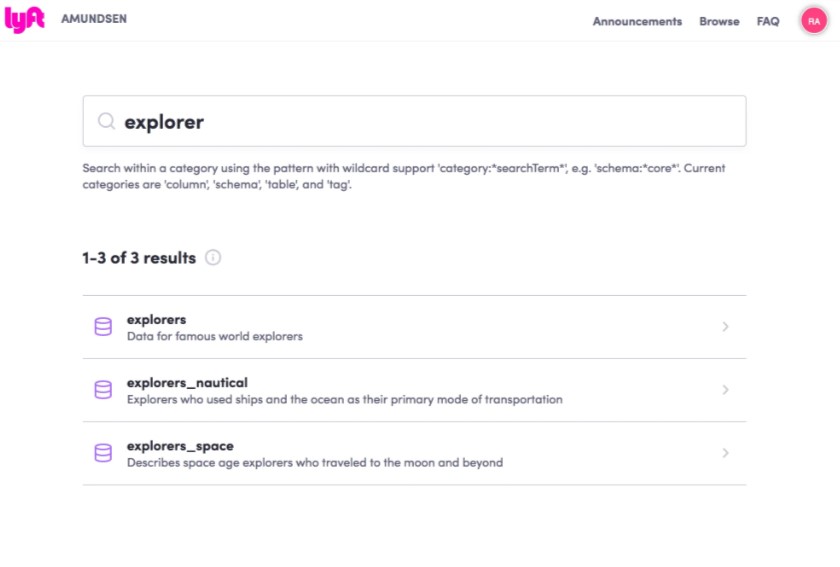
Os resultados mostram alguns metadados em linha – descrição sobre a tabela, bem como a última data em que a tabela foi atualizada. Esses resultados são escolhidos por correspondência difusa do texto inserido com alguns campos de metadados – nome da tabela, nome da coluna, descrição da tabela e descrições da coluna. A classificação de pesquisa usa um algoritmo semelhante ao Page Rank, em que as tabelas mais consultadas aparecem acima, enquanto as menos consultadas aparecem posteriormente nos resultados da pesquisa.
Página de detalhes:
Depois de selecionar o resultado de sua escolha, você chegará à página de detalhes semelhante à abaixo.
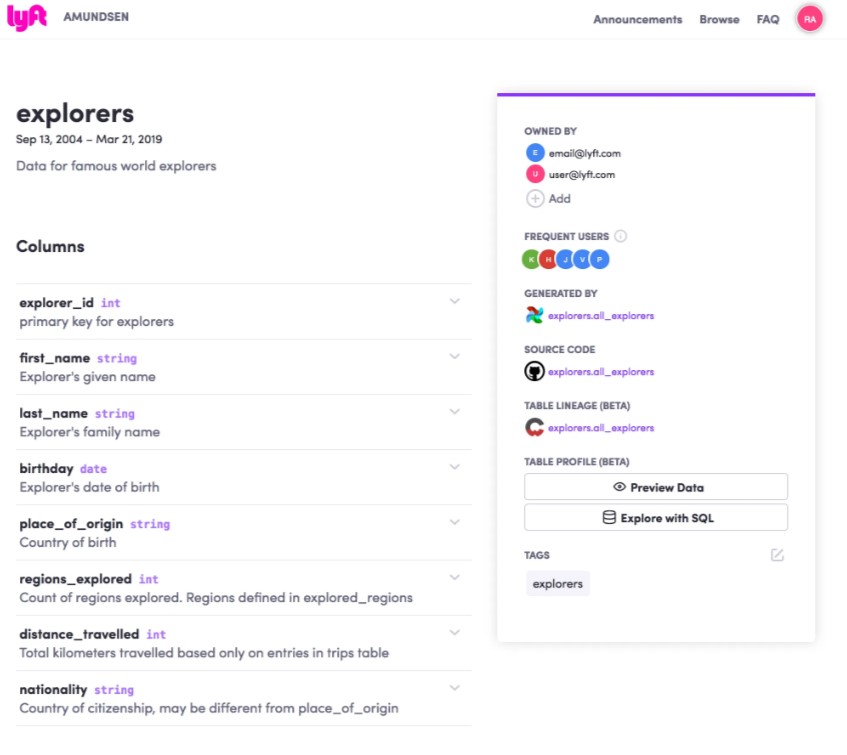
A página de detalhes mostra o nome da tabela junto com sua descrição selecionada manualmente. A lista de colunas junto com as descrições segue. Uma seta azul especial perto de uma coluna mostra que é uma coluna popular, incentivando os usuários a usá-la. No painel direito, você vê informações sobre o comportamento da tabela. Em outras palavras, quem é o proprietário, quem são os usuários frequentes e um perfil geral dos dados para ver como a contagem de registros está mudando na tabela ao longo do tempo, e você vê as tags associadas à tabela.
Informações como descrições e tags são inseridas manualmente por nossos usuários, enquanto informações como usuários populares são geradas automaticamente através dos registros de auditoria.
A parte inferior da mesma página contém um widget para os usuários nos deixarem qualquer feedback que possam ter.
Clicar em uma coluna revela mais estatísticas sobre essa coluna, como abaixo.

Acima, para a coluna inteira, as estatísticas mostram a contagem de registros, contagem nula, contagem zero, mínimo, máximo e valor médio no último dia de dados, para que os cientistas de dados possam começar a entender a forma dos dados.
Por último, a página de detalhes da tabela também contém um botão de visualização, que se você tiver acesso para visualizar os dados, mostrará uma visualização da última partição diária dos dados, como abaixo. Esta visualização só funciona se você tiver acesso aos dados subjacentes.
Trade offs
Descoberta vs. Curadoria
Muitas vezes temos que encontrar um equilíbrio entre descoberta e curadoria. Por exemplo, se sua organização tivesse apenas um pequeno número de conjuntos de dados, e cada um deles fosse criado manualmente por um conjunto de Engenheiros de Dados, e cada tabela fosse bem nomeada, sob um esquema bem definido, cada campo fosse nomeado apropriadamente e o esquema evoluísse em sincronia com a evolução do negócio, então sua necessidade de descoberta pode não ser tão grande nesse mundo.
No entanto, se você mora em uma organização que cresceu muito rápido, com muitos dados, é improvável que a curadoria e as práticas recomendadas para design de esquema por si só tornem seus usuários produtivos.
Nossa abordagem é ter uma combinação de ambos. Ter um sistema de descoberta (também conhecido como pesquisa), ao mesmo tempo que adota algumas práticas recomendadas sobre nomes e descrições de esquemas, tabelas e campos.
Segurança vs democratização
Outro equilíbrio importante a atingir é entre segurança e democratização. Plataformas de descoberta como a descrita acima democratizam a descoberta de dados para todos na organização, enquanto a equipe de Segurança e Privacidade tem a missão de proteger e salvaguardar dados confidenciais em toda a organização. A questão então é como você equilibra essas duas necessidades aparentemente concorrentes?
Nossa abordagem é dividir os metadados em algumas categorias e dar acesso diferente a cada uma das categorias. Uma boa maneira de fazer isso é:
- Existência e outros metadados fundamentais (como nome e descrição de tabelas e campos, proprietários, última atualização, etc.)
Esses metadados são disponibilizados a todos, independentemente de você ter ou não acesso aos dados. A razão é que, para ser produtivo, você precisa saber se tal conjunto de dados existe e se é isso que você está procurando. O ideal é que você possa descobrir a adequação usando esses metadados fundamentais e, se for isso que você procura, solicitar acesso. A única rara exceção aqui é se a existência de uma tabela ou campo revelar alguma informação privilegiada como os países em que você atua, nesse caso, é melhor consertar o modelo de dados ou modelo de segurança e não fazer segurança por obscuridade.
- Metadados mais ricos (como estatísticas de coluna, visualização)
Esses metadados estão disponíveis apenas para usuários que têm acesso aos dados. Isso ocorre porque essas estatísticas podem revelar informações confidenciais aos usuários e, portanto, devem ser consideradas privilegiadas.
Futuro
Amundsen tem tido muito sucesso na Lyft, com uma taxa de adoção e uma pontuação de Satisfação do Cliente (CSAT) muito altas. O tempo necessário para descobrir um artefacto reduziu-se para 5% da linha de base pré-Amundsen. Os usuários agora podem descobrir mais dados em menos tempo e com maior grau de confiança.
O futuro, como o vemos, reside em aumentar ainda mais a produtividade, adicionando mais recursos, mas, mais importante, em desbloquear um novo caso de uso por meio de todos os excelentes metadados já disponíveis no Amundsen — o caso de uso de conformidade.
Conformidade
Embora o GDPR e as leis de privacidade mais recentes, como a Lei de Privacidade do Consumidor da Califórnia (CCPA), afetem o tratamento de dados de várias maneiras, a concessão de direitos de dados do usuário é uma das mais impactantes. As organizações devem gerir formas de cumprir o exercício destes diversos direitos, tais como os de acesso, correção e eliminação de determinados dados.
Estas leis de privacidade normalmente prevêem certas exceções, como a capacidade de manter determinadas informações devido a obrigações legais, mesmo diante de uma solicitação de exclusão. Até agora, as organizações adotaram um número variado de abordagens para se tornarem compatíveis. Alguns estabeleceram processos manuais para resolver as solicitações de serviços de dados recebidas, enquanto outros colocaram os dados pessoais em quarentena em um local/banco de dados, facilitando o gerenciamento dos direitos do usuário.
No entanto, esse método pode falhar na escalabilidade – tanto à medida que a organização e a quantidade de dados e casos de uso nela contidos crescem, como também quando o número de solicitações de serviço de dados recebidas aumenta.
Uma abordagem escalável é aquela alimentada por metadados. É a abordagem em que uma ferramenta como a Amundsen é usada para armazenar e etiquetar todos os dados pessoais dentro da organização. Essa solução alimentada por metadados pode ajudar uma organização a permanecer em conformidade à medida que os dados e seus casos de uso ou solicitações de serviço aumentam.
Produtividade
Atualmente integramos com Hive, Presto e quaisquer outros sistemas que se integram ao metastore Hive (por exemplo, Apache Impala, Spark, etc.). Estes são os próximos itens em nosso roteiro:
- Adicione pessoas ao gráfico de dados de Amundsen, integrando-o com sistemas de RH como o Workday. Mostre ativos de dados comumente usados e marcados como favoritos.
- Adicione painéis e relatórios (por exemplo, Tableau, Looker, Apache Superset) ao Amundsen.
- Adicione suporte para linhagem em ativos de dados diferentes, como painéis e tabelas.
- Adicione eventos/esquemas (por exemplo, registro de esquema) ao Amundsen.
- Adicione streams (por exemplo, Apache Kafka, AWS Kinesis) ao Amundsen.
Conclusão
Com grandes quantidades de dados, o sucesso na utilização completa dos dados não reside nos dados, mas nos metadados. Lyft construiu uma plataforma de descoberta de dados, Amundsen, que funcionou muito bem para melhorar a produtividade de seus cientistas de dados por meio de uma descoberta de dados mais rápida.
Ao mesmo tempo, há muito valor que uma solução baseada em metadados pode oferecer no espaço de conformidade, no rastreamento de dados pessoais em toda a infraestrutura de dados. Devemos esperar muito investimento nessa área no futuro.
Fique ligado na próxima postagem do blog detalhando a arquitetura do aplicativo de descoberta de dados e o mecanismo de metadados que o alimenta!
Obrigado a Max Beauchemin, Andrew Stahlman, Beto Dealmeida pela revisão do post.
Adaptado e traduzido de: https://eng.lyft.com/amundsen-lyfts-data-discovery-metadata-engine-62d27254fbb9